前言
在性能敏感场景下,除了常规的优化方案,如何能从代码底层提高代码性能,例如,一个toC的web H5,静态资源可以压缩图片、CDN加速、懒加载、雪碧图,框架级别有虚拟DOM,React还有useMemo,useCallBack等方法优化,那么除过这些以外,在性能敏感场景下,我们还有什么方法能提高性能呢,本文整理分享了团队内部总结的遍历方法案例
由于 js 是 JIT 的,并不会有 AOT 优化,因此各类迭代方式的选择就显得尤为重要了 —— 因为没有静态编译因此不同的迭代方式或多或少都会有额外的 runtime 开销,本文将对 js 里最常用的 for、forEach、for-of、for-in、Object.entries 进行考察和评估,下面是具体分析过程
for & while
这是 js 提供的最基础的循环控制流,跟 C、Java 里的 for 是一样的语义,能直接对应汇编的 JMP 指令,因此通常认为 for & while 是无开销的迭代方式,粒度也最细 —— 因此除了写着繁琐一点没什么硬伤了,性能是最好的。
forEach 呢?
通常认为 forEach 不会比 for 慢多少,但这是对 “单个大数组” 来说的,比如长度为一百万的 number[ ] 做求和,此时不会有多少差别;
但真实业务中并不存在这么多的大数组情况,100 长度的数组就是 90% 分位了,此时 forEach 内闭包 + stack-frame 开销就不能忽略了 —— 也就是说多次遍历相对短的数组更符合业务实际场景。
为此,构造下面两个求和实现:
forEach 求和
1 | function fn1(arr) { |
for 求和
1 | function fn2(arr) { |
forEach 慢三倍:重复求和长度为 100 的数组对比
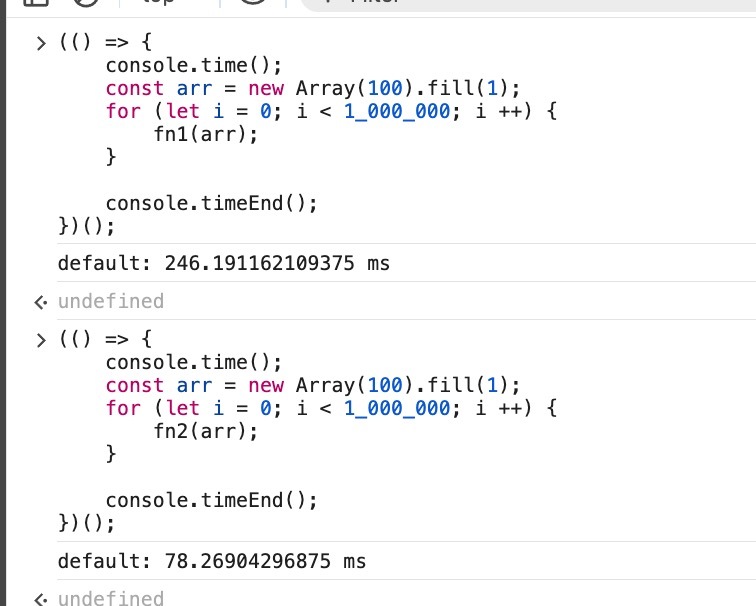
🌟 结论:更推荐使用 for (forEach 通常比 for 慢 3 倍左右)
原因:
- forEach 本身调用会新开调用栈,然后对于 “回调” 来说如果 arr 比较短的话,是不会走 TurboFan 深度优化的机器码的。(时间太短了,调用没几次就结束了)
- forEach callback 本身是一个函数,每次都会创建一个新的,会有额外开销,这个内存开销是 28 字节,而 for 是 0 开销的
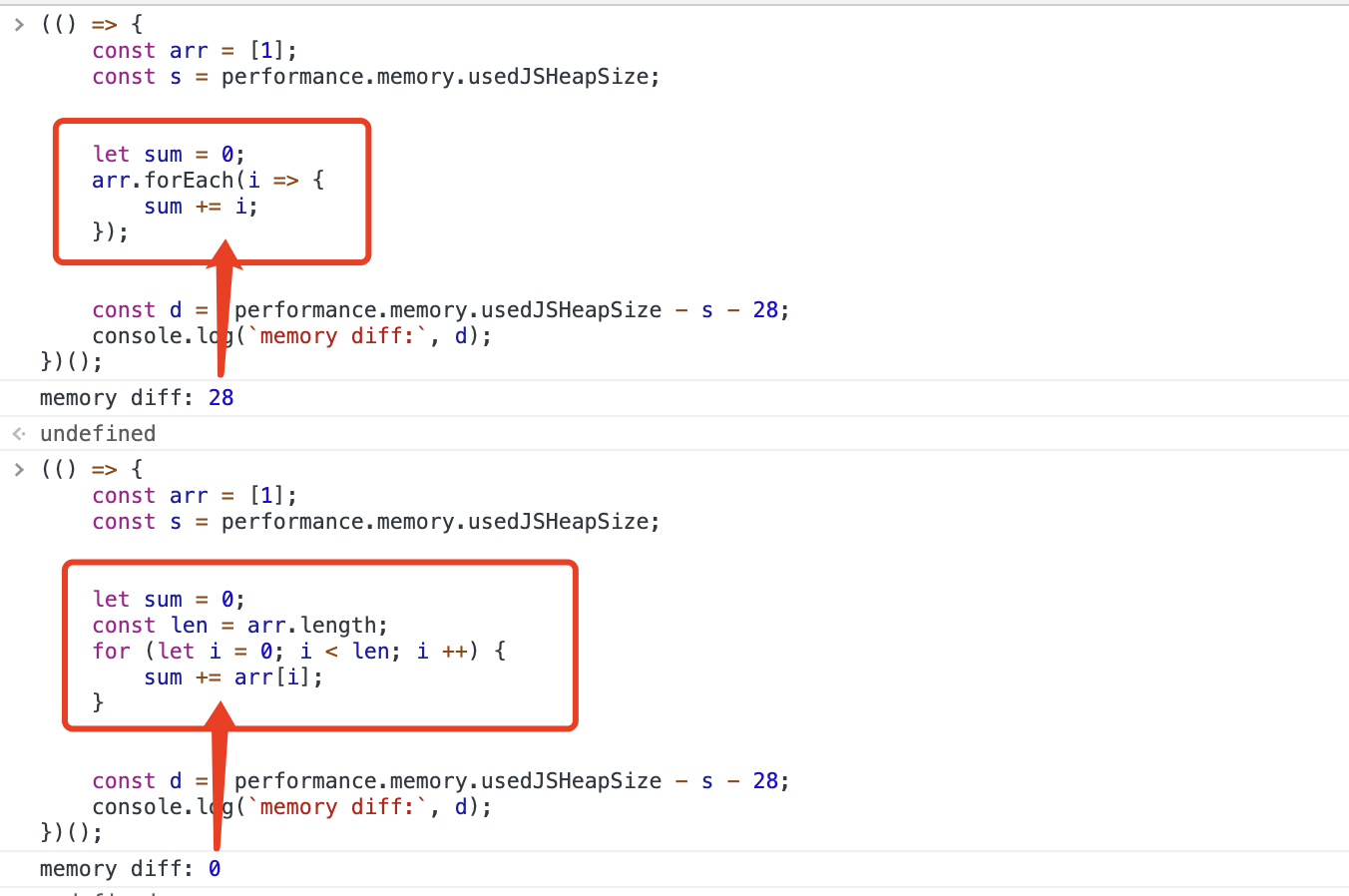
写这篇文章指出这个问题并不是说禁用 forEach,而是应当在性能敏感场景注意一下迭代方式的选择对性能的影响。
其他的 map、filter、reduce 呢?
—— 其实最核心的问题是:for 循环其实直接对应汇编 JMP 指令,而数组的函数式方法做不到这么好的编译效果,最后就带来较大的开销了
for-of 呢?
在 ES6 环境下,对于数组来说基本无差别(略慢一点点) 。。 但是。。。
但是 for-of 是为 generator 设计的 … 于是 …
但是!!!for-of 语义上是为 generator 使用的 —— 这意味着使用在 ES5 下使用 for-of 的时候要引入相当重型的无栈协程 runtime: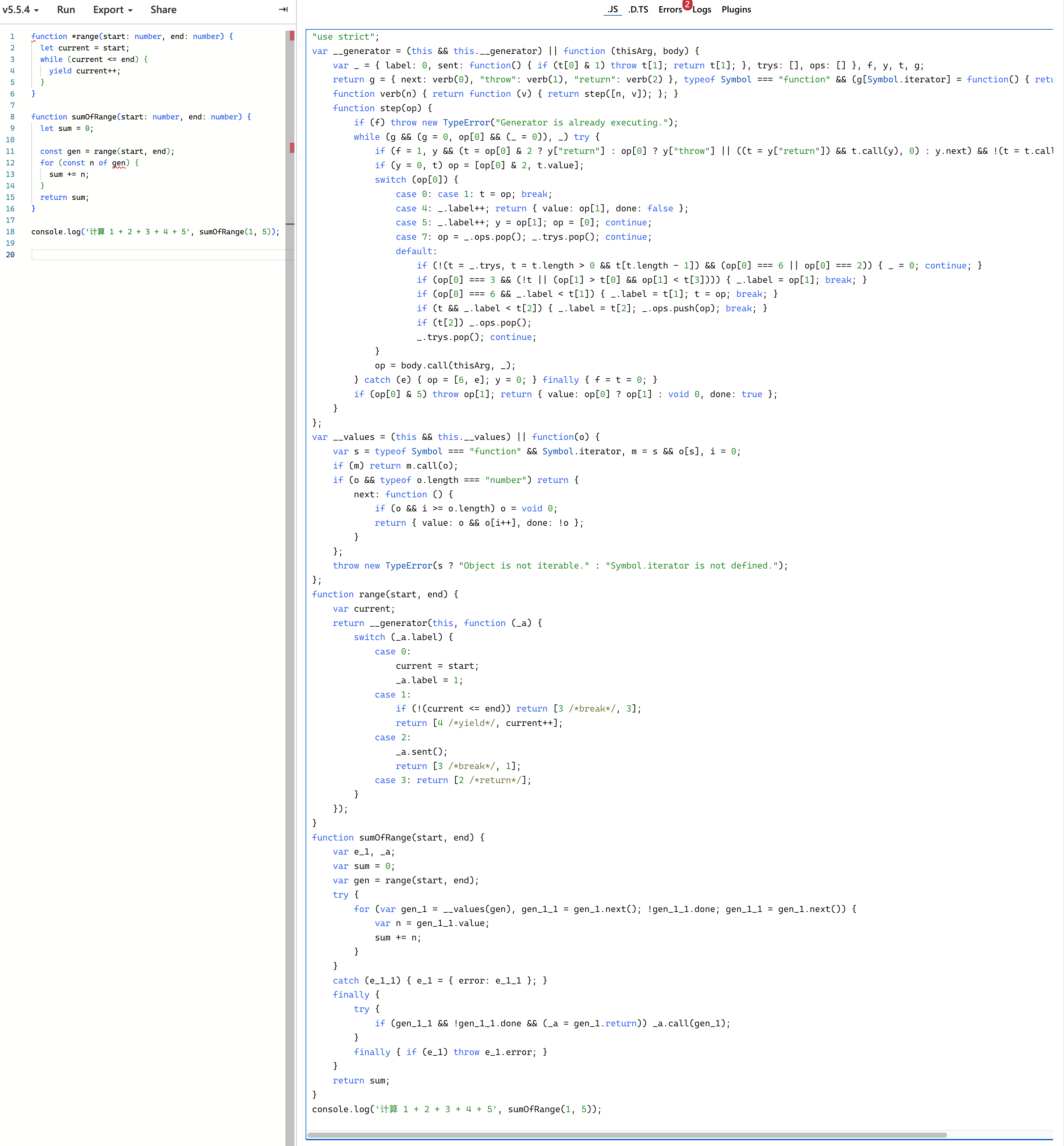
要是这个 runtime 用 C++ 写的倒也还好,但它是 js 写的,因此慢上加慢 —— 最终高频场景下这东西编译成 ES5 后,在 chrome 下性能极其糟糕: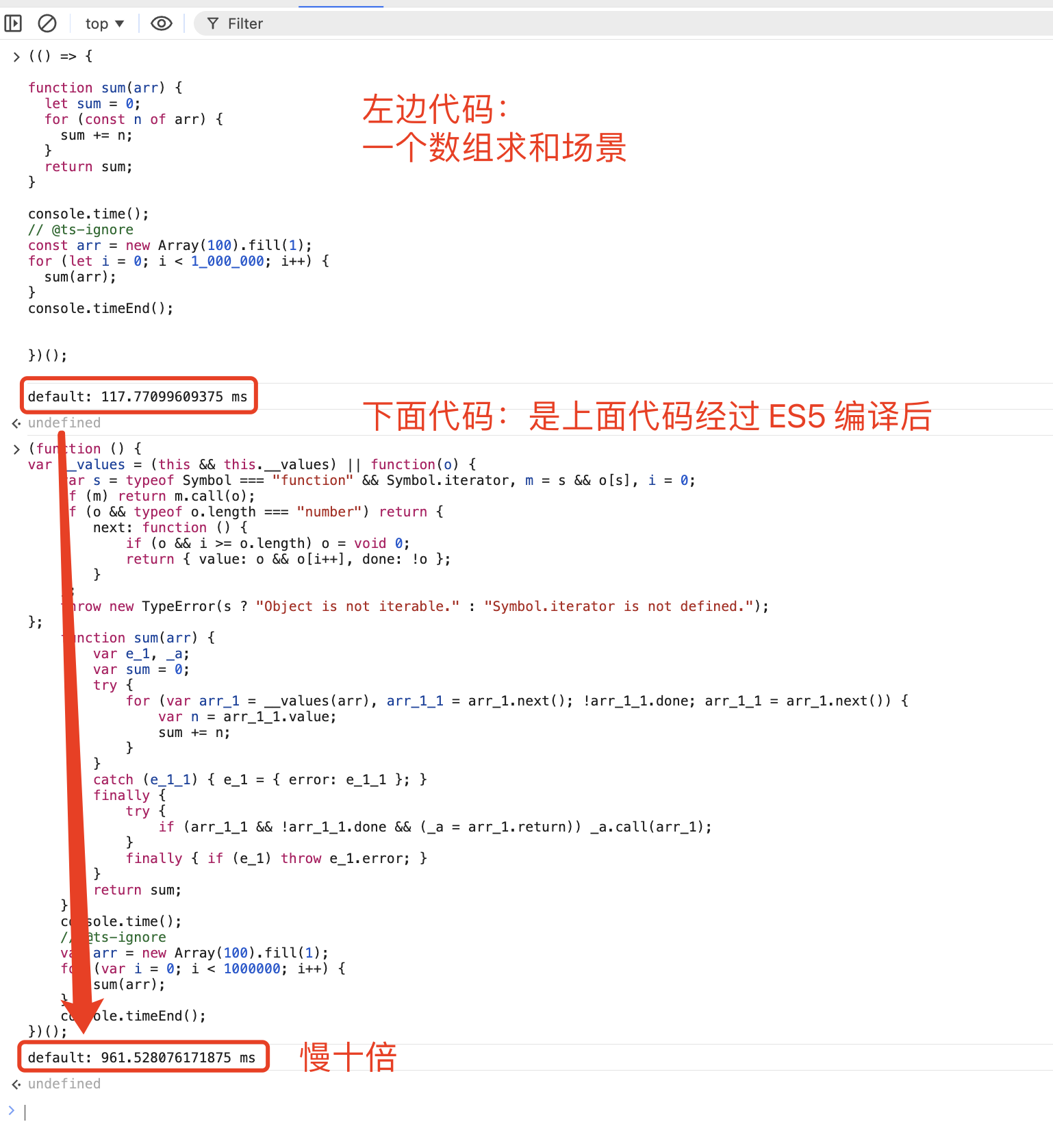
其他浏览器也会不同程度的变慢:
safari 差 6 倍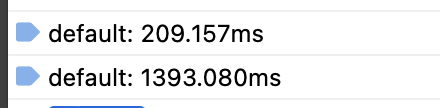
firefox 差 2 倍
🌟 结论:不推荐给数组使用,除非你真的需要
虽然 for-of 的语义很静态,比较好做优化,但真实场景下无法判断会不会引入 babel 之类的 runtime 造成极度劣化
for-in 呢?
这个特性相当有历史了,它甚至是 ES5 时代就支持的东西,IE 都支持:
根据 V8 团队写的https://v8.dev/blog/fast-for-in 这篇来看,for-in 规范里没有很明确底层 runtime 的逻辑导致 firefox 和 v8 的 for-in 实现执行顺序完全不一样,但他们两者都「符合规范」 。。。。 而由于 for-in 的规范描述相当动态导致其不是很好做优化,比如下面这段代码在 firefox 和 chrome 下输出顺序不同:

后续 ES 标准委员会为了修复这个问题又搞了一大堆的补丁,整个过程看起来极其复杂:

最后 V8 还狠狠鄙视了一波 tc39:

截止到 2024 年,上面 for-in 还是一样的调用序,V8 出于性能问题没有严格按照 for-in 上面的十条补丁来实现。
for-in 性能对比
自测了一下,由于 for-in 规范的复杂性和不完备性,性能都不如自己写的遍历
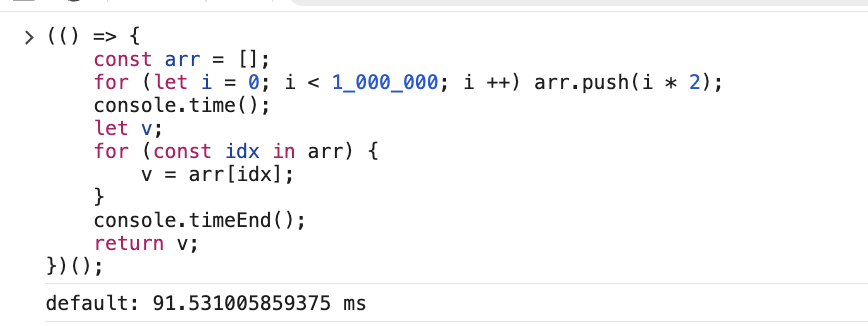
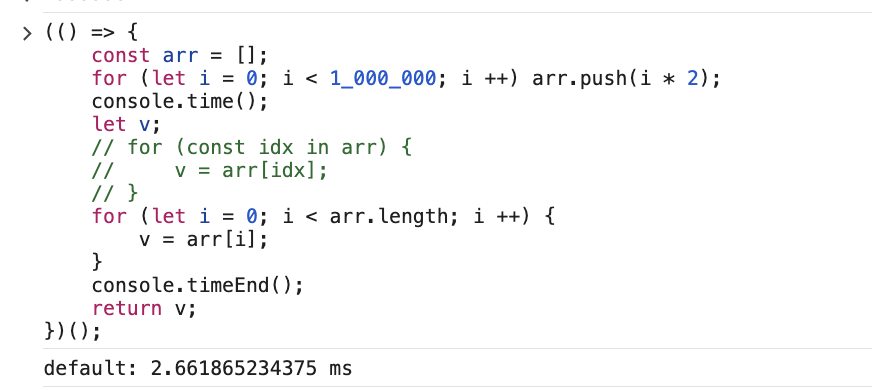
常规数组遍历:差距极大
arr: number[] 的遍历,for-in 慢了五十倍,为什么?最主要的原因是 for-in 拿到的 key 是一个字符串而不是一个自增的整数,性能非常糟糕
业务里是否有对 arr 的 for-in 操作?
对象遍历
Slow Properties
慢对象的场景下,keys 性能更好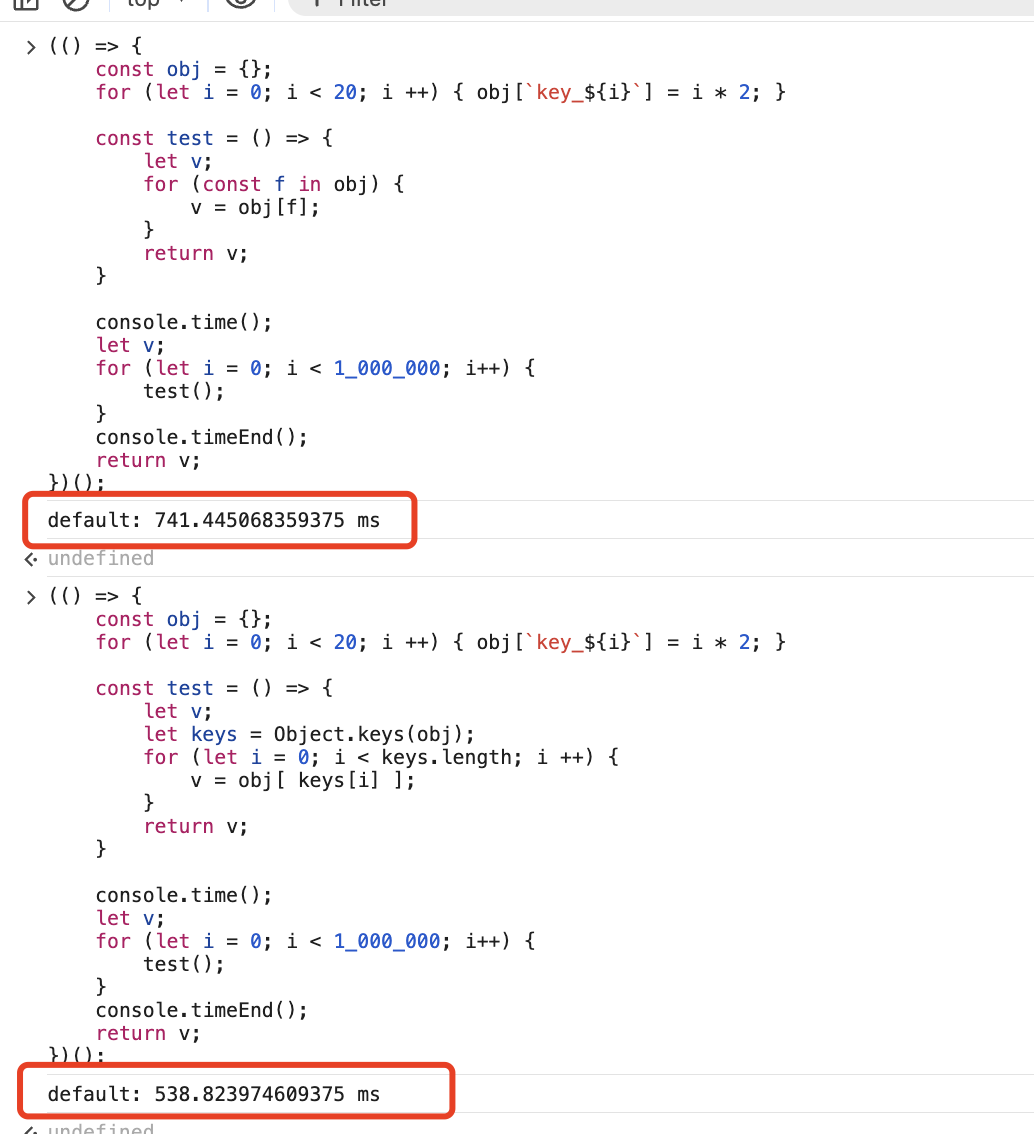
Fast Properties (EnumCache)
带 hiddenmap 的情况下,for-in 更好(推测是不需要 Object.keys 分配一个数组导致):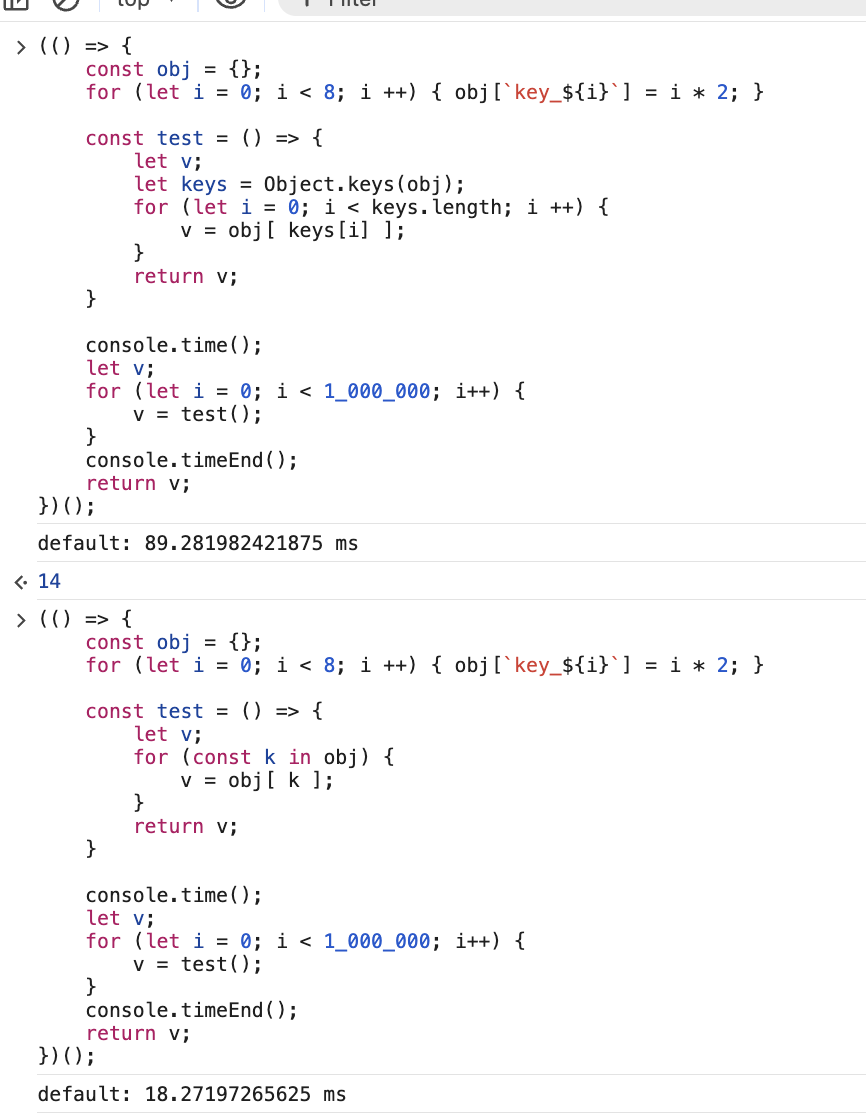
而且从配合 ICs 的 case 来看,for-in 里动态 key 查找应该还帮做了 ICs 优化:
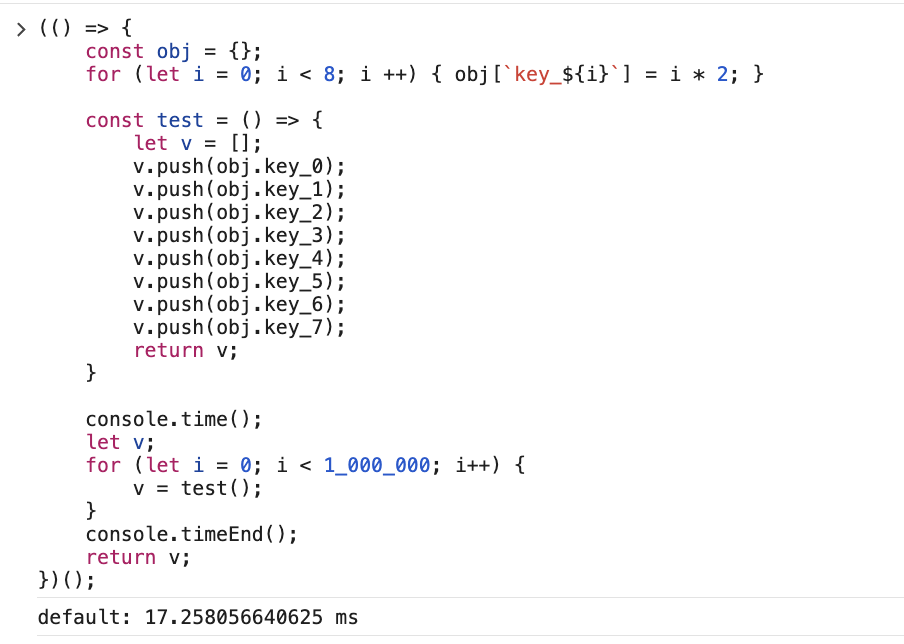
EnumCache
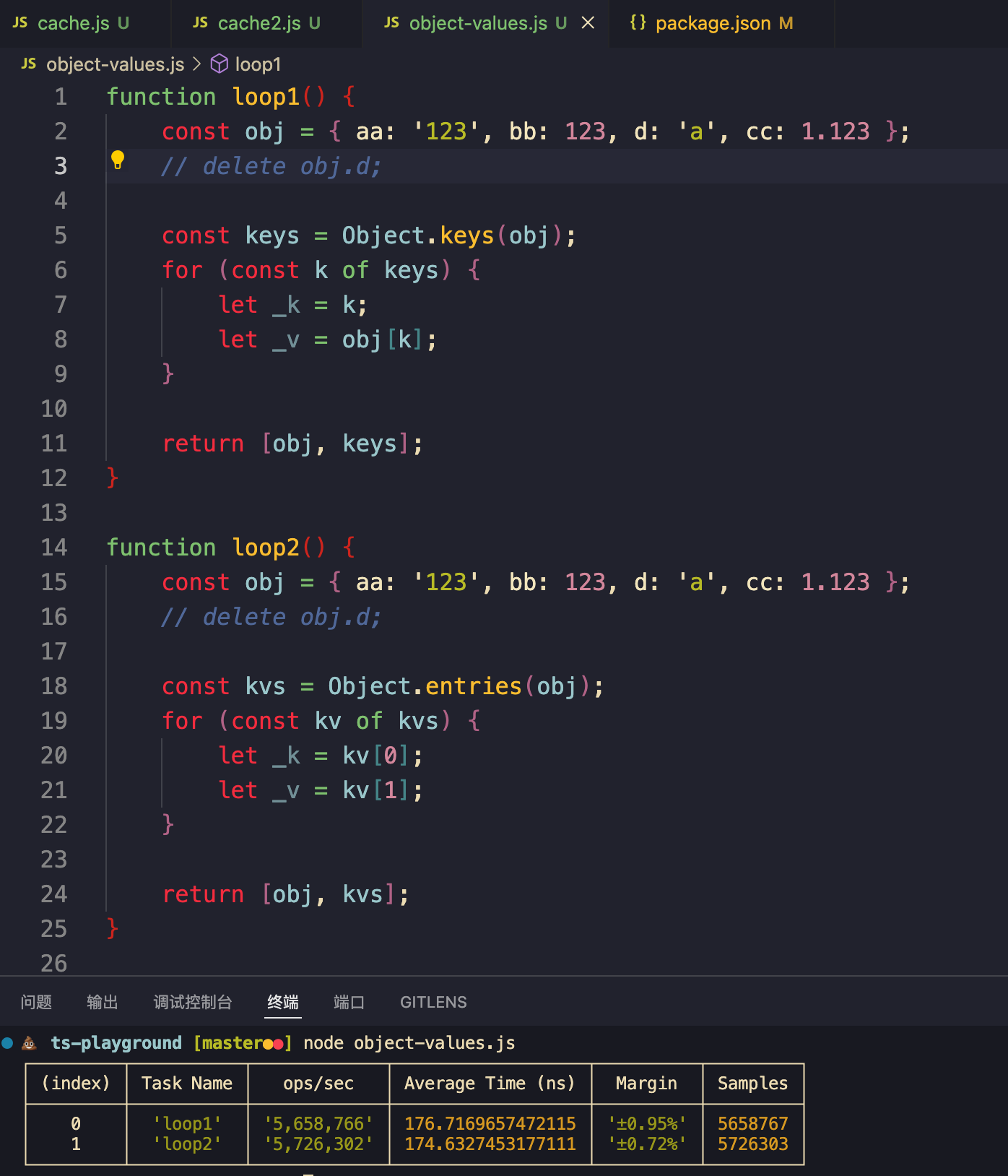
根据 V8 对象模型,对象可以工作在不同模式下:
1.Fast Properties:用 hiddenMap 追踪对象类型,成员存储在 in-object 上
2.Slow Properties:key 比较多 or delete key 的时候会变成 Slow Properties,此时成员存储在 *properties 上
显然,Fast Properties 从原理上就拥有更快的 Object.keys 速度,可以非常容易的加缓存上去,V8 实现了一个叫做 EnumCache 的字段在 hiddenClass 上

这使得百万次调用 Object.keys 的耗时几乎可以忽略不计:

🌟 结论:明确是 fast-properties 的场景下推荐使用 (此外不要用 for-in 处理数组)
fast-properties 场景下 for-in 遍历更快,因为不需要分配 arr 数组;
而在 slow-properties 的场景下情况下就不如了(枚举 key 的速度太慢)
Object.entries 呢?
除了上述几种关键字方式遍历外,还有一种是通过 Object.entries 去枚举遍历对象。
fast-properties 下:没区别
slow-properties:会慢约两倍
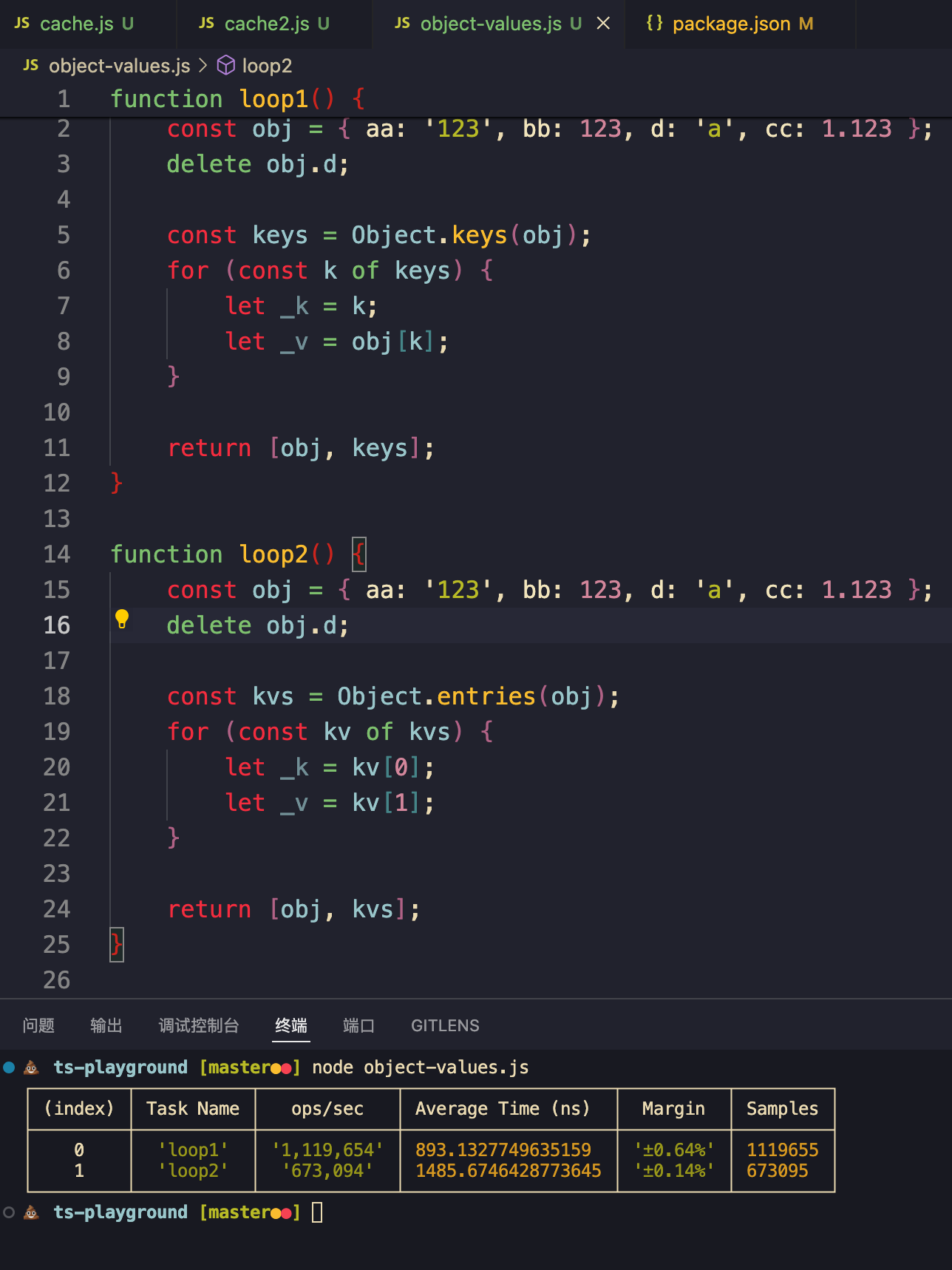
🌟 结论:非必要不使用
建议配合 for-in 或者手动 Object.keys 的方式来做遍历
🌟 全总结
性能区别
时间性能上 for >= for-in > forEach > Object.entries >= for-of 内存性能上,for 是无开销的直接对应汇编 JMP 指令,其他的或多或少都可能涉及内存分配,尤其是 Object.entries写算法尤其注意迭代方式的选择
如果你在写算法、写排版、写数据层,那么优先使用 for 来写,其他场景看具体需求,一般不需要关心选择哪种迭代方式(这种情况推荐 for-of 和 forEach 这类)
好看不代表性能好
js 没有 AOT 优化,多数优化都是通过 JIT 做的,比如 ICs、字节码等等,这也意味着:好看好读的代码性不一定能好,而且还有 Terser Webpack 这些东西也很喜欢改代码 —— 这些都可能导致劣化。
比如读完上面的文章再看类似这样的迭代模式:

确实好看,但是这里叠了 Object.entries + for-of 下来,在 ES5 下估计要慢很多
